OCR / Extraktionsmodul
Das OCR / Extraktionsmodul in DocView Capture ist dafür verantwortlich, gescannte Bilder in maschinenlesbaren Text umzuwandeln und strukturierte Daten zu extrahieren.
Hier werden Dokumente von Rohseitenbildern in durchsuchbaren Text und Feldwerte transformiert, die in nachgelagerte Indexierungs- und Workflow-Prozesse eingespeist werden.
OCR / Extraktionsworkflow
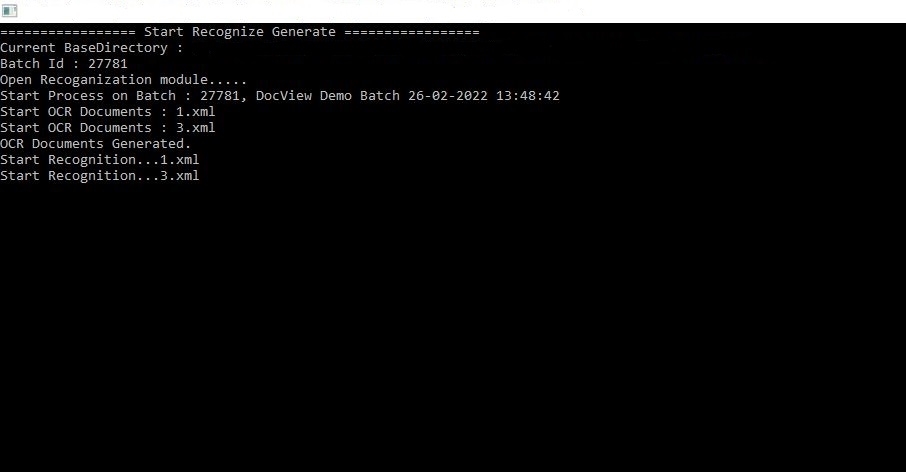
1. Batch-Initialisierung
- Das System identifiziert den Batch über Batch ID.
- Beispiel: Batch 27781, DocView Demo Batch 26-02-2022 13:48:42.
2. OCR-Prozess starten
- Jedes Dokument im Batch wird nacheinander verarbeitet.
- Dateinamen (z. B.
1.xml,3.xml) werden für die Speicherung der OCR-Ausgabe erstellt.
3. Texterkennung
- Die OCR-Engine analysiert die Seitenbilder.
- Wandelt gescannten Text, Zahlen und Zeichen in maschinenlesbaren Text um.
- Erstellt XML-Ausgabe mit erkannten Texten und Positionsmetadaten.
4. Datenauszug
- Nach Abschluss der OCR identifiziert die Extraktions-Engine Felder basierend auf Vorlagen und Regeln.
- Beispiel-Felder: Rechnungsnummer, Datum, Lieferantenname, Gesamtbetrag.
- Die Erkennungsphase validiert extrahierte Werte mittels Regulärer Ausdrücke oder Lookup-Tabellen.
5. Ergebnis-Speicherung
- Extrahierte Daten werden der XML-Struktur des Dokuments zugeordnet.
- Sowohl der Roh-OCR-Text als auch die extrahierten Felder werden für nachgelagerte Module (Review, Index, Export) gespeichert.
Wichtige Operationen im Log
- OCR-Dokumente starten –
1.xml,3.xml: OCR-Prozess beginnt und erstellt Textausgabe pro Seite. - OCR-Dokumente erstellt – OCR erfolgreich abgeschlossen, Ausgabe in strukturierter XML gespeichert.
- Erkennung starten –
1.xml,3.xml: Datenextraktion beginnt, Feldwerte aus OCR-Ergebnissen werden übernommen.
Toolbar-Übersicht
Home Tab
- OCR starten – OCR für den ausgewählten Batch ausführen.
- Prozess stoppen – Laufende OCR-Sitzung unterbrechen.
- Erneut verarbeiten – OCR für ausgewählte Dokumente erneut ausführen.
View Tab
- OCR-Ausgabe-Viewer – Erkannten Text anzeigen.
- Fehlerprotokoll – Zeigt OCR-/Erkennungsfehler an.
Einstellungen Tab
- OCR-Engine Auswahl – Engine auswählen (Tesseract, ABBYY, etc., abhängig von Umgebung).
- Sprachpakete – Sprache für OCR konfigurieren.
- Extraktionsregeln – Feldregeln, Regex und Lookup-Referenzen definieren.
Statusanzeigen
- In Bearbeitung – OCR läuft.
- Abgeschlossen – OCR/Extraktion für das Dokument fertig.
- Fehlgeschlagen – OCR konnte nicht verarbeitet werden (niedrige Scanqualität oder nicht unterstütztes Format).