Module OCR / Extraction
Le Module OCR / Extraction dans DocView Capture est responsable de la conversion des images scannées en texte lisible par machine et de l’extraction des données structurées.
C’est ici que les documents sont transformés à partir d’images brutes en texte exploitable et consultable et en valeurs de champs pour les workflows et l’indexation en aval.
Workflow OCR / Extraction
1. Initialisation du Lot
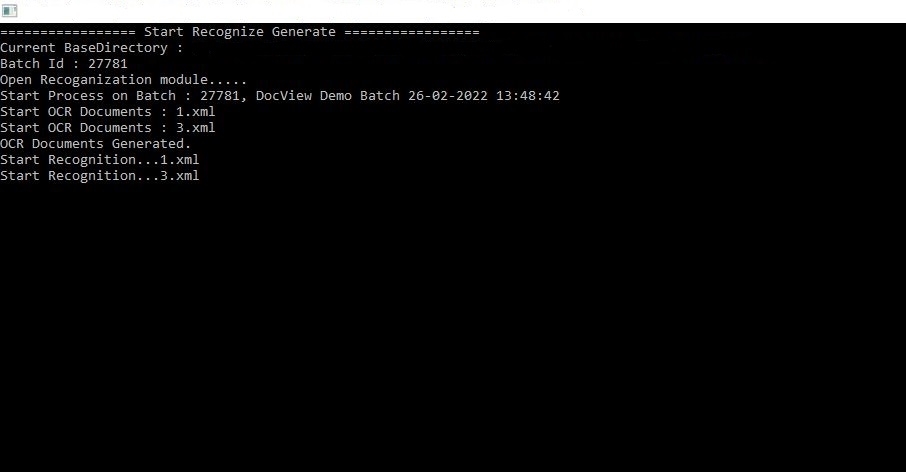
- Le système identifie le lot via son ID de lot.
- Exemple : Batch 27781, DocView Demo Batch 26-02-2022 13:48:42.
2. Démarrage du Processus OCR
- Chaque document du lot est traité séquentiellement.
- Des noms de fichiers (ex.
1.xml,3.xml) sont générés pour stocker la sortie OCR.
3. Reconnaissance de Texte
- Le moteur OCR analyse les images de pages.
- Convertit le texte, les chiffres et les caractères scannés en texte exploitable par machine.
- Produit une sortie XML contenant le texte reconnu et les métadonnées de position.
4. Extraction de Données
- Après OCR, le moteur d’extraction identifie les champs selon les modèles et règles définis.
- Exemples : Numéro de facture, Date, Nom du fournisseur, Montant total.
- La phase de reconnaissance valide les valeurs extraites avec des expressions régulières ou tables de référence.
5. Stockage des Résultats
- Les données extraites sont liées à la structure XML du document.
- Le texte OCR brut et les champs extraits sont stockés pour les modules suivants (Review, Index, Export).
Opérations Clés dans le Journal
- Démarrer OCR Documents –
1.xml,3.xml: début de l’OCR pour chaque page. - Documents OCR générés – OCR terminé avec succès, sortie sauvegardée en XML structuré.
- Démarrer Reconnaissance –
1.xml,3.xml: extraction de données, récupération des valeurs de champs à partir de l’OCR.
Barre d’Outils
Onglet Accueil
- Démarrer OCR – Exécuter OCR sur le lot sélectionné.
- Arrêter le processus – Interrompre la session OCR en cours.
- Reprocesser – Relancer OCR pour des documents sélectionnés pour plus de précision.
Onglet Vue
- Visionneuse OCR – Prévisualiser le texte reconnu.
- Journal d’Erreurs – Affiche les erreurs OCR / reconnaissance.
Onglet Paramètres
- Sélection du moteur OCR – Choisir l’engine (Tesseract, ABBYY, etc.).
- Packs de Langue – Configurer la langue pour l’OCR.
- Règles d’Extraction – Définir règles de champs, regex et tables de référence.
Indicateurs d’État
- En traitement – OCR en cours.
- Terminé – OCR / extraction terminé pour le document.
- Échoué – OCR impossible (scan de mauvaise qualité ou format non supporté).