Módulo OCR / Extracción
El Módulo OCR / Extracción en DocView Capture se encarga de convertir imágenes escaneadas en texto legible por máquina y extraer datos estructurados.
Aquí los documentos se transforman de imágenes de página sin procesar a texto utilizable y buscable y valores de campos que alimentan la indexación y workflows posteriores.
Flujo de Trabajo OCR / Extracción
1. Inicialización del Lote
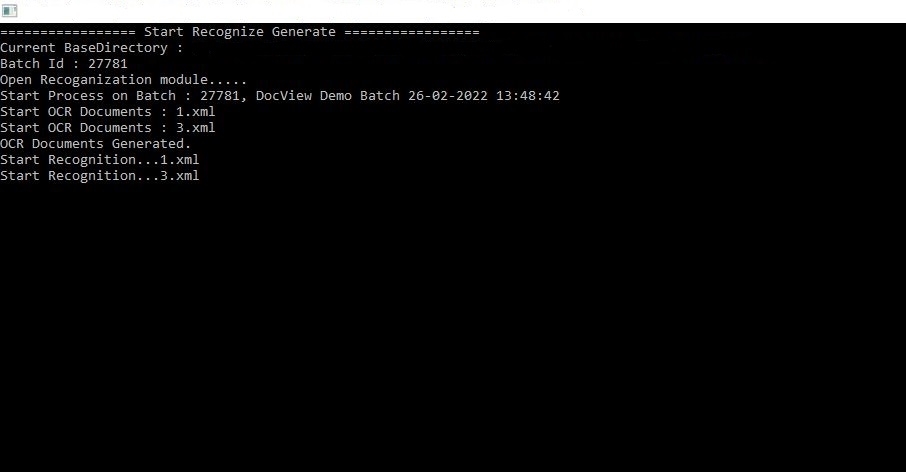
- El sistema identifica el lote mediante su ID de Lote.
- Ejemplo: Batch 27781, DocView Demo Batch 26-02-2022 13:48:42.
2. Inicio del Proceso OCR
- Cada documento del lote se procesa secuencialmente.
- Se generan nombres de archivo (p.ej.,
1.xml,3.xml) para almacenar la salida OCR.
3. Reconocimiento de Texto
- El motor OCR analiza las imágenes de las páginas.
- Convierte texto, números y caracteres escaneados en texto legible por máquina.
- Produce una salida XML con el texto reconocido y metadatos de posición.
4. Extracción de Datos
- Después de OCR, el motor de extracción identifica campos según plantillas y reglas definidas.
- Campos de ejemplo: Número de Factura, Fecha, Nombre del Proveedor, Importe Total.
- La fase de reconocimiento valida los valores extraídos mediante expresiones regulares o tablas de consulta.
5. Almacenamiento de Resultados
- Los datos extraídos se vinculan a la estructura XML del documento.
- Tanto el texto OCR en bruto como los campos extraídos se guardan para módulos posteriores (Review, Index, Export).
Operaciones Clave en el Log
- Iniciar OCR Documentos –
1.xml,3.xml: comienza el OCR generando salida de texto para cada página. - Documentos OCR Generados – OCR completado con éxito, salida guardada en XML estructurado.
- Iniciar Reconocimiento –
1.xml,3.xml: comienza la extracción de datos, obteniendo valores de campos del OCR.
Barra de Herramientas
Pestaña Home
- Iniciar OCR – Ejecutar OCR en el lote seleccionado.
- Detener Proceso – Detener sesión OCR en curso.
- Reprocesar – Ejecutar OCR nuevamente en documentos seleccionados para mayor precisión.
Pestaña Vista
- Visor de Salida OCR – Previsualizar texto reconocido.
- Registro de Errores – Muestra errores de OCR / reconocimiento.
Pestaña Configuración
- Selección de Motor OCR – Elegir motor (Tesseract, ABBYY, etc.).
- Paquetes de Idioma – Configurar idioma específico para OCR.
- Reglas de Extracción – Definir reglas de campos, regex y referencias de búsqueda.
Indicadores de Estado
- Procesando – OCR en progreso.
- Completado – OCR / extracción finalizado para el documento.
- Fallido – OCR no pudo procesar (baja calidad de escaneo o formato no soportado).